

95% of AI pilots deliver no measurable impact on the bottom line. That’s the headline finding from MIT’s State of AI in Business 2025 report.
Concerningly, the pattern is getting worse, not better. In 2025, 42% of companies abandoned most of their AI initiatives. The year before, that number was 17%.
The technology works. The demos are impressive. The business cases get approved. And then six months later, the pilot is shelved or running in a corner of the business with no route to production.
This blog is about the difference between a pilot that demos well and a system that runs operations. Why that difference exists, what blocks it, and what needs to be true before anyone commits to scaling.

The UK rail industry's AI Action Plan confirms the pilot problem
On 28 April 2026, GBRX (the strategic technology body for Britain’s railway) launched the Artificial Intelligence in Rail Action Plan at the Science Museum in London. The plan’s stated aim is to move the sector “beyond isolated pilots to a coordinated, railway-wide approach.”
The barriers it names are the same three that show up in every cross-sector AI failure analysis: incomplete or inconsistent data, weak governance and assurance frameworks, and a shortage of AI skills and organisational readiness.
Toufic Machnouk, Managing Director of GBRX, put it directly: the application of industrial AI in safety-critical environments “is not inevitable and requires considered, strategic and purposeful action.”
Rail is not the outlier here. It’s the latest sector to put the diagnosis in writing.
Healthcare, financial services, manufacturing, and utilities are running the same pattern. Gartner forecasts that over 40% of agentic AI projects will be cancelled by the end of 2027, citing escalating costs, unclear business value, and inadequate risk controls.
The pilot trap is sector-agnostic.
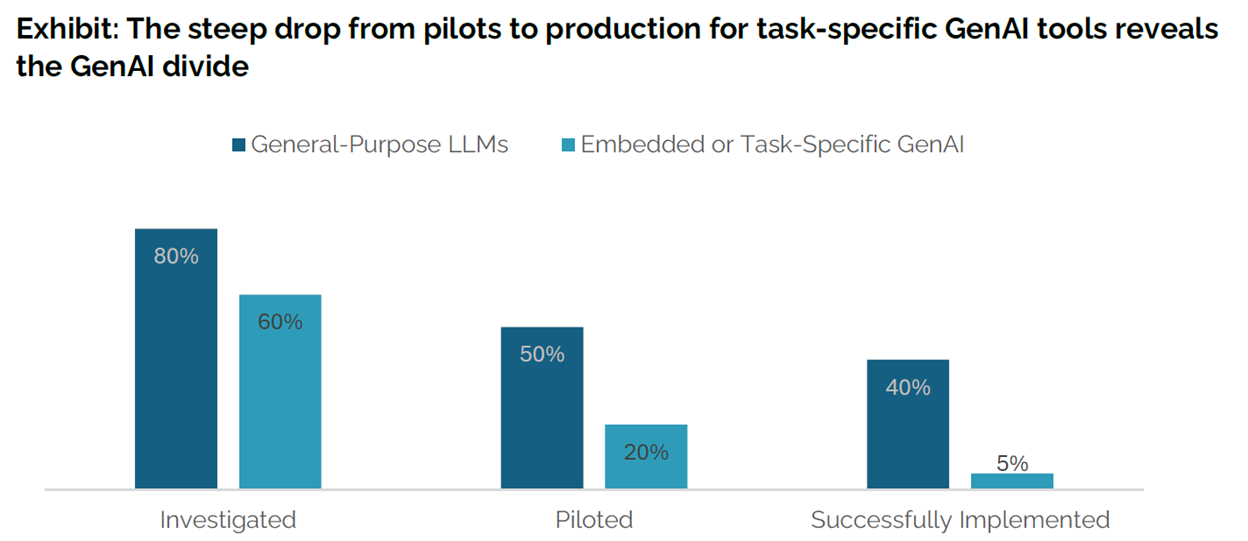
Why 95% of AI pilots fail to deliver business value
Pilots are designed to win. Three things stack the odds in their favour.
- First, they run on clean, curated data prepared specifically for the test. Datasets get extracted, cleaned, normalised, and handed to the model in a state that production systems will never deliver.
- Second, they have one team’s full attention and a protected budget. No competing priorities, no shared infrastructure, no procurement queue.
- Third, success is measured by model accuracy or user feedback, not P&L. A pilot can hit every internal metric and still produce zero revenue impact.
Here’s how that plays out.
A predictive model hits 94% accuracy in a controlled test environment. Executive leadership sees the number and approves a scaling decision. Six months later, the model is shelved because the live data feed it needs doesn’t exist, the operations team it was built for has been restructured, and the integration work was never costed.
Pilots prove technical feasibility. But they don’t prove operational viability. The conditions that make a pilot succeed are the same conditions that make scaling difficult.
Three hidden blockers that don’t show up in AI demos
Every pilot that stalls at production stalls for one of three reasons. They rarely show up in the demo. They always show up in the rollout.
#1. Production data the AI can’t actually access
Gartner identifies poor data quality as the root cause of 85% of failed AI projects. Pilot data is curated. Production data is fragmented across multiple systems, often in incompatible formats and rarely available in real time.
For an operator running depot management, scheduling, ticketing, telematics, and ERP across separate platforms, a model that performs well on a clean export will not perform well against the live feeds. The integration work needed to change that is rarely scoped during the pilot phase. It gets discovered later, costed later, and becomes the reason the project gets paused.
A predictive maintenance model trained on 18 months of cleaned sensor data needs continuous, real-time access to live telematics in production. If that pipeline doesn’t exist, the model can’t run. The pilot was never going to tell you that.
#2. Ownership no one wanted to claim
Pilots have a project sponsor. Production needs an accountable owner with budget authority and a decision mandate.
In most enterprises, AI goes across IT, operations, safety, finance, and procurement. Each function has a stake. None has the lead. Without a named owner before the pilot starts, the scaling decision becomes a political negotiation that no one wins.
Only 37% of organisations invest adequately in change management for AI initiatives. The 63% that don’t are the same organisations whose pilots stall the moment they need cross-functional sign-off.
#3. Integration with the systems that actually run operations
Pilots run alongside operational systems. Production AI runs inside them. That distinction sounds small. It’s the difference between an AI tool that gives a recommendation an operator may or may not act on, and an AI system that updates the schedule, triggers the maintenance ticket, or reroutes the vehicle.
BCG’s framing is useful here:
“AI transformation is 10% algorithms, 20% data and technology, and 70% people, processes, and cultural change. Most pilots only test the first 10%.”
Integration is also where the costs hit. The model itself is rarely the expensive part. The connectors, the security review, the workflow redesign, and the user training are. None of those costs appear on the pilot invoice.
Why specialist AI vendors outperform internal builds
MIT data shows a trend in how successful AI implementations are built. Vendor-led AI deployments succeed about 67% of the time. Internal builds succeed about 33% of the time.
That’s a 2x difference, and it holds across sectors and use cases.
Specialist vendors have already solved the integration problems for their use case. They’ve debugged the failure modes. They’ve built the workflow connections. And they know what the production environment will demand because they’ve shipped to it before (plenty of times).
Internal builds underestimate three things.
- The cost of ongoing maintenance.
- The depth of integration work.
- And the difficulty of keeping AI talent in-house once the build phase is over.
The first version ships and then the team that built it moves on, leaves, or gets reassigned. The model decays. No one owns the retraining cycle. Which means, the system that was meant to be a strategic asset ends up as a maintenance burden.
This is where the choice of partner gets weight. The wrong vendor produces another pilot. The right vendor produces a production system. The vetting process for that decision is different from the vetting process for software procurement, and most enterprises don’t have it set up.
A 30-minute product demo and two reference calls aren’t enough.
The key questions are:
- have they deployed this in production,
- in a sector like yours,
- against data conditions like yours,
- with integration constraints like yours?
If the answer to any of those is no, you’re funding their first attempt.
What needs to be true before you scale an AI project (Quick checklist)
Five conditions separate the 5% of pilots that scale from the 95% that don’t.
- A named operational owner. One person, with budget authority and the mandate to make scaling decisions. Not a steering committee. Not a working group. A name on a document. If the org chart can’t produce that name before the pilot starts, the pilot will stall when it needs cross-functional sign-off.
- Data the AI can access in production conditions. Not a clean export. Not a sample. The real, live, integrated feed it will need to run against once it’s deployed. Test the data pipeline before the pilot, not after. If the production data isn’t ready, the pilot is testing the wrong thing.
- A pre-agreed kill criterion. A specific number that triggers a stop. Without one, pilots run forever because no one wants to be the person who killed the AI project. The kill criterion protects the budget, the team, and the credibility of the next AI initiative. Agree it on day one.
- A scale plan written before the pilot starts. What does production look like? Which systems does it integrate with? Who maintains it? What does it cost to run for three years? If those answers come after the pilot proves itself, the pilot is doing the wrong job. Production planning belongs at the start.
- Vendor selection based on operational fit, not demo polish. A 30-minute product demo and two reference calls aren’t enough. Operational fit means the vendor has deployed this exact use case in production, in a sector like yours, against data conditions like yours, with integration constraints like yours. Anything less and you’re funding their first attempt.
These conditions are what production-grade AI looks like before the production phase starts.
Where this leaves you
If you’ve run a pilot that didn’t scale, you’re in the 95%. That’s not a comment on the team or the technology. It’s a comment on the conditions around the pilot.
The conversation that changes the outcome happens before the next pilot, not after the last one.
Most operators don’t need a bigger AI strategy. They need a clearer set of pre-conditions, a named owner, and a vendor selection process built around operational reality.
Ready to find AI solutions that match your operational reality?
Contact us: info@mindtheaigap.com | Call us free: 0800 009 6408